
Understanding Deep Web Intelligence
What is The Deep Web?
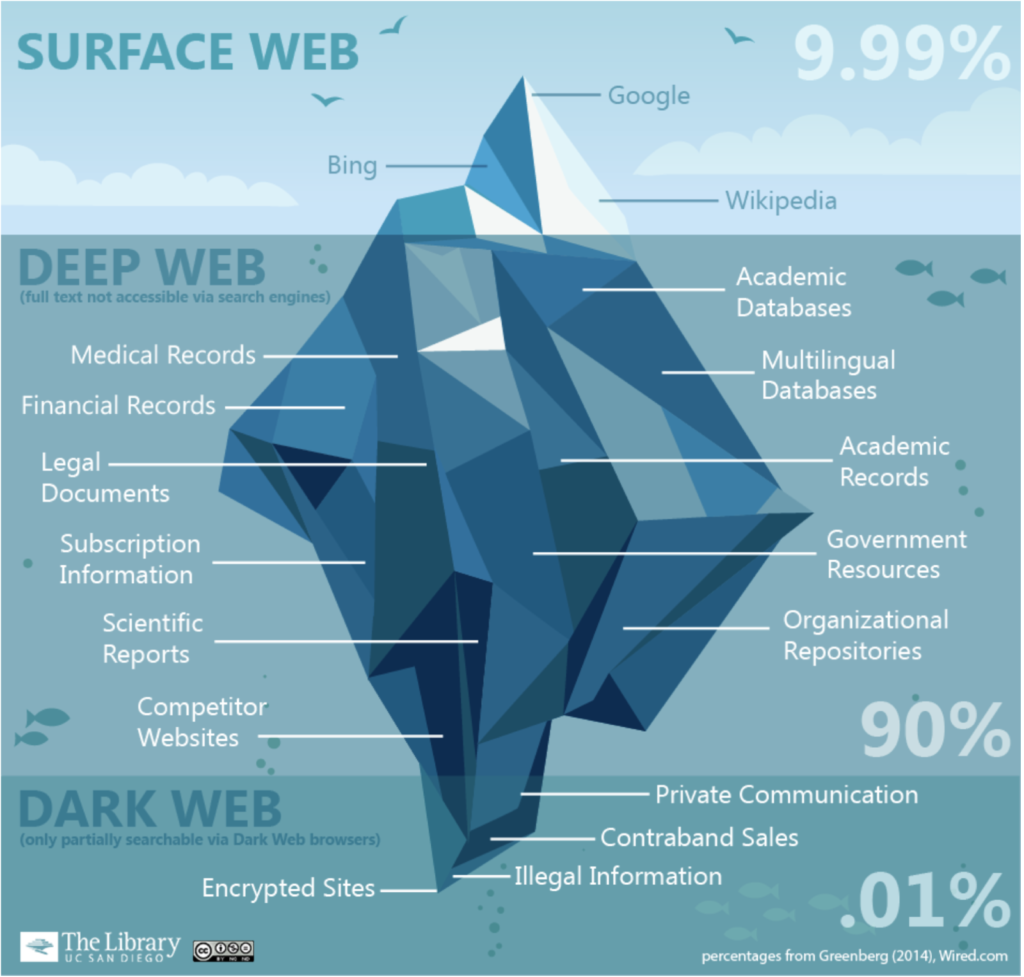
When examining what exactly the deep web is, it is important to also understand how to access it. All content on the web is classified into three categories: the surface web, the deep web, and the dark web. The surface web is anything that you can access from a normal search engine, such as Google or Bing. For context, this is often depicted as the visible tip of an iceberg, with the surface web accounting for less than 10% of all web content. Information on this part of the web includes open-source intelligence (OSINT) data you can access on public websites, public social media posts, internet publications, and other open-source services like Reddit and Wikipedia.
The invisible web, which includes both the deep web and the dark web, refers to the part of the internet that is not indexed by search engines. Deep web information is not accessible through normal searches because it is usually stored in a database not coded in HTML. For example, Google may take you to the main search interface of a university’s library database, but it generally cannot search the specific content within that database.
The deep web is estimated to cover anywhere from 90–99% of all web content, making it the largest subset of the internet by a large margin. Deep web content includes anything that requires sign-in credentials or anything that sits behind a paywall. Also included in this category is content that has been purposely blocked from indexing and web crawlers by its owners.
The smaller subset of the invisible web is the dark web. Dark web sites cannot be accessed by normal browsers but rather must be accessed via a hidden services network, often called an ‘onion’ browser, such as Tor. These browsers use hidden IP addresses, obscuring the sites’ content, hosts, and users. Offering several layers of anonymity and privacy, the dark web is a common marketplace for illegal activities.
Deep Web Intelligence Sources
Deep web intelligence is mostly found in online databases. Examples of this type of information include,
- Personal records (academic, legal, financial, and health)
- Email inboxes
- Cloud storage drives
- Company intranets & organization repositories
- Subscription information
- Scientific studies & reports
- Academic databases
- Government resources
How Can I Access Deep Web Sources?
In order to access deep web databases, researchers may leverage various methods to locate their desired database, or they may use a deep web search engine that can locate the information for them. Here, we’ve defined some common and useful deep search engines.
DuckDuckGo
Though commonly known as a privacy search engine for the surface web, DuckDuckGo is more robust than the typical browser. The site pulls results from over 500 search tools, accessing deep web content that is not visible on Google. The service also offers an onion browser where users can access the dark web.
USA.gov
This official website of the United States government allows you to browse public websites of every federal agency as well as federal, state, and local governments. This resource also provides official information regarding policy, elected officials, government jobs, grants, taxes, etc. Most of the information on the site will not appear in a Google search.
BizNar
Biznar, is often referred to as a ‘Google alternative’ that provides aggregated high-quality content from over 100 different search engines. Users find it particularly useful when looking for specific information. Each search query produces only high-quality content that is collated and ranked.
The Directory of Open Access Journals (DOAJ)
This deep search engine provides access to academic Journals. With current access to over 10,000 journals with 2.5 million articles across all subjects, the DOAJ is an excellent research tool, providing more sources than Google Scholar.
The Internet Archive or “Wayback Machine”
Commonly referred to as the Wayback Machine, the Internet Archive is a non-profit organization that provides a library of digitized material, including websites, games, software applications, media, images, and countless publications. This source not only provides current web content, but also content that is no longer available.
Gathering Deep Web Research
Because most deep web content does not show up in a Google search, researchers often need to be creative when locating sources. The challenge with deep web research is to shift the focus from finding the content to finding the doorway to the content.
To begin searching for databases, it is helpful to search for a subject term and the word “database,” like “drug” database, or “public records” database. Analysts will also check searchable lists, guides, and directories that contain indexed information on a topic. This could be anything from extensive public personnel directories to an article stating the 50 most populated cities in the United States.
Even non-scholarly associations, foundations, and organizations will often have excellent sources in list form. Examples include associations and organizations directories, as well as state agency databases. Think tanks can also be a good starting point when drilling into a particular subject. Expert studies that emerge from think tanks often reference sources from a wide variety of disciplines.
Gathering deep web intelligence can be a more labor-intensive process than gathering OSINT on the surface web. Identifying and locating sources often requires careful planning, problem solving, and creativity. Once you understand the ways to access this type of data, the deep web can be a limitless trove of intelligence for any investigation.







